Basics of DNA Structure
 |
| Twelve base-pairs of DNA in its most common conformation, called B-DNA. This space-filling model shows that double-helical DNA is a compact and dense package of atoms. This density attests to the precise fit of many atoms with each other. |
The primary function of nucleic acids in living organisms is the storage, transport, and translation of information. Genes are information, written in the side-chains of DNA. The best understood type of genetic information is a recipe for making a specific protein, like hemoglobin or an immunoglobulin chain.
Like proteins, nucleic acids are long chains of relatively simple units, called nucleotides, which are analogous to amino-acid residues in proteins. As in proteins, nucleic acids have a repetitious backbone with protruding side chains. Whereas proteins have 20 different types of side chains, nucleic acids have only four, abbreviated A, T, C, and G. Because of the chemical properties of these side chains, they are usually called bases.
The top portion of the cartoon below represents DNA in schematic form. Its backbone is aqua ribbon, and side chains, or bases, are the little boxes labeled A, T, C, and G. In normal or “resting” DNA, there are two chains coiled around each other—the famous double helix. The bases bond non-covalently to each other, holding the two chains together. But the bonding is very specific: A on one chain is always opposite T on the other, and C is always opposite G.
 |
| Diagram of DNA chain (top) and DNA replication (bottom).Figure modified from that of I, Madprime at http://en.wikipedia.org/wiki/DNA_replication, used in accord with license agreement at http://creativecommons.org/licenses/by-sa/3.0/deed.en |
A gene recipe for a particular protein is written in the four-letter alphabet of As, Ts, Gs, and Cs. Three consecutive bases, called a codon or triplet, specify one amino acid in the protein encoded by the gene. So a gene for a 100-residue protein is 300 bases long. Your DNA contains such recipes for each one of the roughly 23,000 proteins your cells can make. (This might sound like a lot of information, but protein-encoding genes account for only about 2% of your DNA. Scientists are still discovering the many tasks done by the other 98% of your DNA. It appears that most of DNA serves some function but a surprising amount of it is still mysterious.)
Replication
When a cell divides, each new cell must contain a full set of DNA information. So the DNA must be copied, or replicated, before cell division. Replication entails separating the two chains of the double helix, and then making new chains on each of the old ones. This process is illustrated in the bottom portion of the previous figure.
The old chains are called templates. The machinery that builds the new chains will install only an A in a new chain opposite to a T in the template, and so forth. This constraint means that the two sets of double-helical DNA will be identical, as in the bottom of the figure. But copying is not perfect; a small percentage of errors occur, resulting in the occasional mismatch (G-T in the figure). In the next generation of division by the cell that receives the mismatch, one of the next-generation double helices will have an A-T pair where the other has a G-C pair. Such changes in the information encoded in DNA are called mutations. (The mutation in the figure is called “C-to-T”, because correct replication would have resulted in a C in place of the T shown in the white circle.)
Molecular structures show why A-T and G-C are natural couples
The binding of oxygen to hemoglobin, of antigens to antibodies, of DNA bases to each other—all of these interactions have something in common: specificity. Specificity means precise fit, with little chance for error. Specificity assures effective interactions among molecules.
The pairing of A with T and G with C is good example of specificity. A few relatively simple pictures will show you why nature makes so few mistakes in copying from a template strand to produce a new DNA strand.
 |
| Ball-and-stick model of the same DNA as the space-filling model above. This model appears very open, but remember that there is very little empty space in DNA. Blue and yellow ribbons follow the contours of the backbones of the two strands. |
 |
| Base pairs from the previous model. On the left is an A-T base-pair, on the right, G-C. |
Gene to protein: transcription and translation
Precisely how are recipes written into genes, and how does the machinery of the cell read these recipes and prepare proteins properly? In brief, the letters of a gene (lots of letters A, T, G, and C that encode a protein, are transcribed. This term means copied, by a process much like replication, but using slightly different building blocks, into a new strand called RNA. This is like sort of like copying a recipe from a prized family cookbook (DNA) onto a chit of paper (RNA) that you can place on the kitchen counter and not worry about getting sauce on your heirloom.
An RNA strand that encodes a protein is called a messenger RNA (mRNA). A messenger RNA leaves the confines of the nucleus for the wide world of the cytoplasm, where it encounter chefs, call ribosomes, that can read the recipe and do the cooking, and process called translation. Reading the recipe entails translating a the code of RNA sequence into the language of protein sequence, a sequence of building blocks which you know by now as amino acids.
Here is a brief summary of replication, transcription, and translation:
 |
| Source: http://www.vcbio.science.ru.nl/en/virtuallessons/cellcycle/trans/ |
Do we know the details of this code? Yes, in detail, from work that garnered one Nobel Prize after another in the 1950s and 1960s. Here’s how each group of three successive bases of mRNA (called a triplet) are read as amino acids.

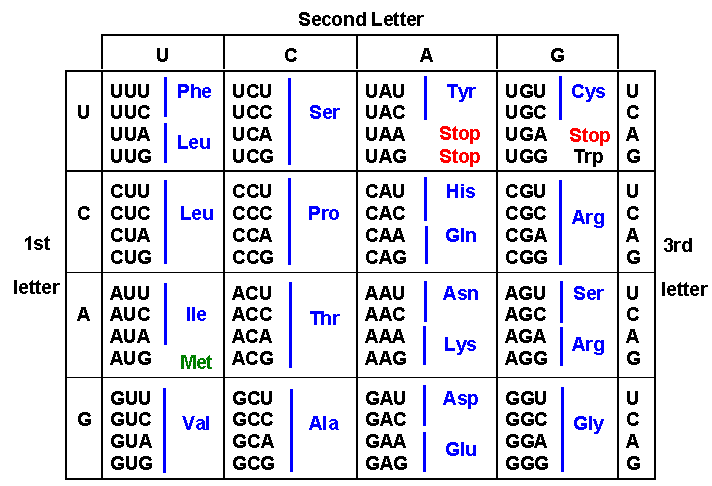 |
| Example: The triplet UCG codes for the amino acid serine (Ser). A mutation that changes C to G in a serine codon gives UGG, which codes instead for tryptophan (Trp). Notice that mutations involving the third letter of a triplet often do not change the amino acid encoded, making the code more resistant to mutation. Source: http://biology.kenyon.edu/courses/biol114/Chap05/Chapter05.html |
An mRNA contains a “start” region that guides the chef to the first triplet, which specifies the N-terminal amino acid of the protein. The chef finds this ingredient, amino-acid #1, on a special holder called a transfer RNA; then reads the second triplet, finds the next ingredient on a similar holder; and finally, transfers amino-acid #1 onto amino-acid #2, leaving holder #1 empty, and leaving holder #2 carrying a very short protein comprising only two amino-acid residues. Repeating this process gives three residues on holder #3, four on holder #4, and so on. At some point, the chef encounters a triplet that, in effect, says, “Stop.” The chef releases the protein from the last holder, and sets it off on its own, to fold up properly and carry out its function.
Click this link to view a video depicting DNA packaging, replication, transcription, and translation:
http://www.youtube.com/watch?v=4PKjF7OumYo
Consequences of mutation
Mutation in a gene that encodes a protein might change the identity of one amino-acid residue in the protein. If the residue is crucial to the protein’s function, then it could alter or destroy the protein’s ability to do its job. For example, in hemoglobin, the side chain involved in binding oxygen is crucial to oxygen transport. (The amino acid is called histidine, and its codon is either CAT or CAC.) A hemoglobin mutant with some other amino-acid residue at that site would not bind oxygen properly or at all. A fertilized egg containing such a mutation would not survive; the mother might not even realize that a brief pregnancy had occurred.
Some types of mismatch mutations can be more severe. Three triplets, TAA, TAG, and TGA do not code for an amino acid, but instead signal the end of the gene; in other words, they are stop codons. A mutation that changes an amino-acid code to a stop code would mean that a shortened protein chain would be produced. For example, the triplet CAA codes for an amino-acid called glutamine. A C-to-T mutation, like the one shown in the replication diagram above, would change the triplet to TAA, a stop codon. Synthesis of the protein would stop at that point, rather than incorporating a glutamine into the chain and continuing. The result would almost certainly be a shortened, non-functioning protein.
Mutations are quite common, but most of them miss crucial parts of genes. It is estimated that a human baby’s DNA contains more than 50 new mutations, the majority of which come from the father’s sperm, which results from many more generations of cell division than does the mother’s egg. The older that father, the larger the number of mutations. So it is indeed fortunate that most of these mutations are of no consequence.